应用介绍
- ollama 是一个开源的大型语言模型服务工具,专为用户在私有环境上便捷部署、训练和运行大型语言模型。
- ollama 提供了丰富的预训练模型库,涵盖了各种自然语言处理任务,如文本生成、翻译、问答等。
- ollama 提供了灵活的自定义选项,允许用户根据自己的需求调整模型的行为。
- ollama 可以让用户在离线环境下使用LLM,这对于隐私敏感或网络连接不稳定的情况非常有用。
- ollama 常用于自然语言处理、机器翻译、人工智能等领域的教学和研究,以及开发和测试新的自然语言处理应用程序。
使用指南
- 平台提供了 ollama 的 0.5.7 版本,并预置了一些常用预训练模型,安装路径为
/opt/app/ollama/0.5.7。
- 由于 ollama 的运行环境已经封装的非常易用了,用户只需要申请GPU资源即可开始使用。平台支持在slurm公共集群运行,也支持在个人实例运行。
- 用户如果没有平台作业提交的经验,可以先查看 帮助中心 - 作业系统 部分,了解作业提交的基本概念和操作方法。
在公共集群使用ollama
1. 申请gpu计算资源
由于ollama一般是交互式运行,用户可以用salloc方式申请计算资源,再登录到计算节点上运行。
salloc -p gpu --gres=gpu:1 -n 8
- 命令说明: 指定gpu分区,申请1张gpu卡、8个cpu核心
2. 运行 ollama server
用户申请完资源后,先登录到计算节点。设置相应环境变量,并启动 ollama 服务
export OLLAMA_MODELS="/opt/app/ollama/0.5.7/models"
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama serve
- 命令说明: OLLAMA_MODELS 指的是 ollama 模型存放的路径,如果不指定该环境,则下载模型时会在个人目录下自动生成目录
.ollama,并将模型存放在该目录下。
3. 运行 ollama 对话模型
用户再打开一个新的窗口,并在计算节点运行如下命令,开始对话:
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama run qwen2.5:32b
- 命令说明: 用户还可以通过
ollama list 命令查看当前环境有哪些模型。
在个人实例使用ollama
1. 申请支持ollama的gpu实例
可以先向管理员咨询哪些个人应用是支持 ollama 的,再创建相应的实例。
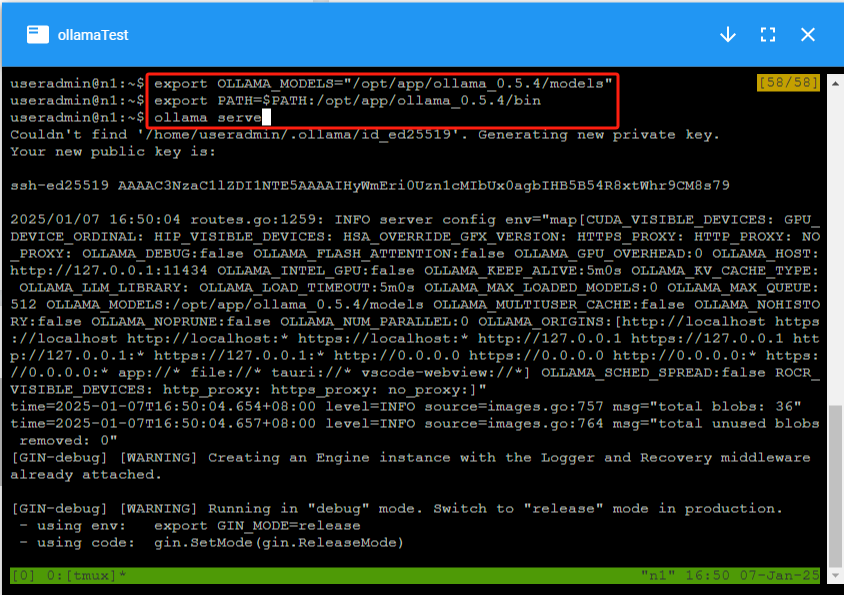
2. 运行ollama服务
打开实例的控制台,运行 tmux 终端工具,在第一个窗口执行如下命令:
export OLLAMA_MODELS="/opt/app/ollama/0.5.7/models"
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama serve
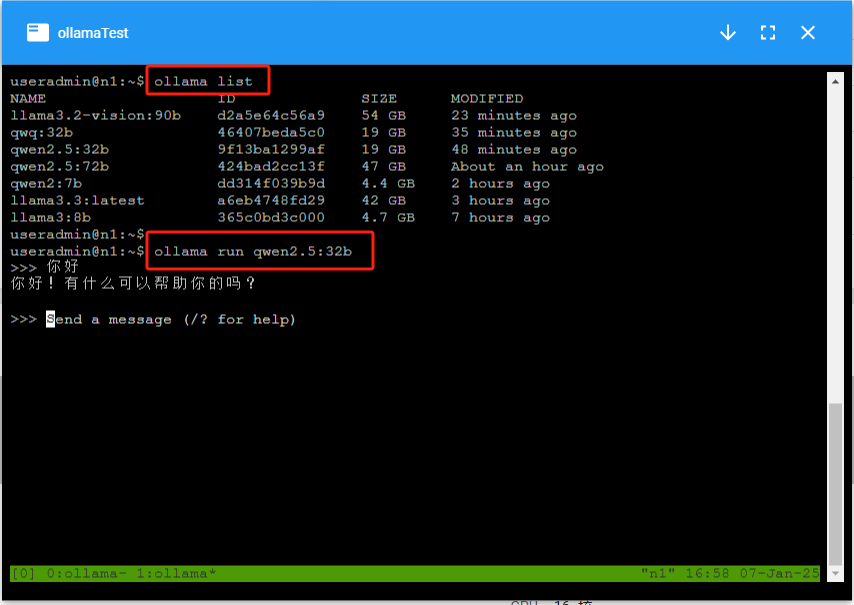
3. 运行 ollama 对话模型
在同一个 tmux 窗口,输入 ctrl + b , 再输入 c ,创建新的tmux窗口。并在新窗口并输入如下命令,开始对话
export PATH=$PATH:/opt/app/ollama/0.5.7/bin
ollama run qwen2.5:32b
参考链接
https://github.com/ollama/ollama
https://techdiylife.github.io/blog/blog.html?category1=c02&blogid=0037
