应用介绍
- PyTorch 是一种开源深度学习框架,以出色的灵活性和易用性著称。这在一定程度上是因为与机器学习开发者和数据科学家所青睐的热门 Python 高级编程语言兼容。
- PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习。使用 Python 编写,因此对于大多数机器学习开发者而言,学习和使用起来相对简单。PyTorch 的独特之处在于,它完全支持 GPU,并且使用反向模式自动微分技术,因此可以动态修改计算图形。这使其成为快速实验和原型设计的常用选择。
使用指南
平台目前提供 个人实例 和 公共集群作业 的 pytorch 使用方式,两种方式的区别是:
- 个人实例:可以直接在jupyterlab页面交互使用pytorch
- 作业:可以提交pytorch作业,在后台长时间训练
平台支持官方提供的多个pytorch版本,包括且不限于如下版本,用户可以根据需要自行选择:
| 版本 | 版本 |
|---|
| 1.8.2(LTS) | 2.2.0 |
| 1.10.0 | 2.2.1 |
| 1.10.1 | 2.2.2 |
| 1.11.0 | 2.3.0 |
| 1.12.0 | 2.3.1 |
| 1.12.1 | 2.4.0 |
| 1.13.0 | 2.4.1 |
| 1.13.1 | 2.5.0 |
| 2.0.0 | 2.5.1 |
| 2.0.1 | |
| 2.1.0 | |
| 2.1.1 | |
| 2.1.2 | |
个人实例方式
1. 通过 “申请资源” 中,找到 “pytorch” 应用模板,创建个人实例
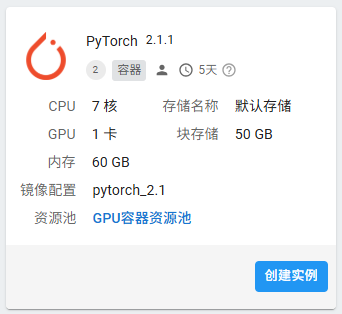
2. 启动实例,并打开用户界面,可以看jupyterlab已经提供了pytorch-2.1.1的虚拟环境

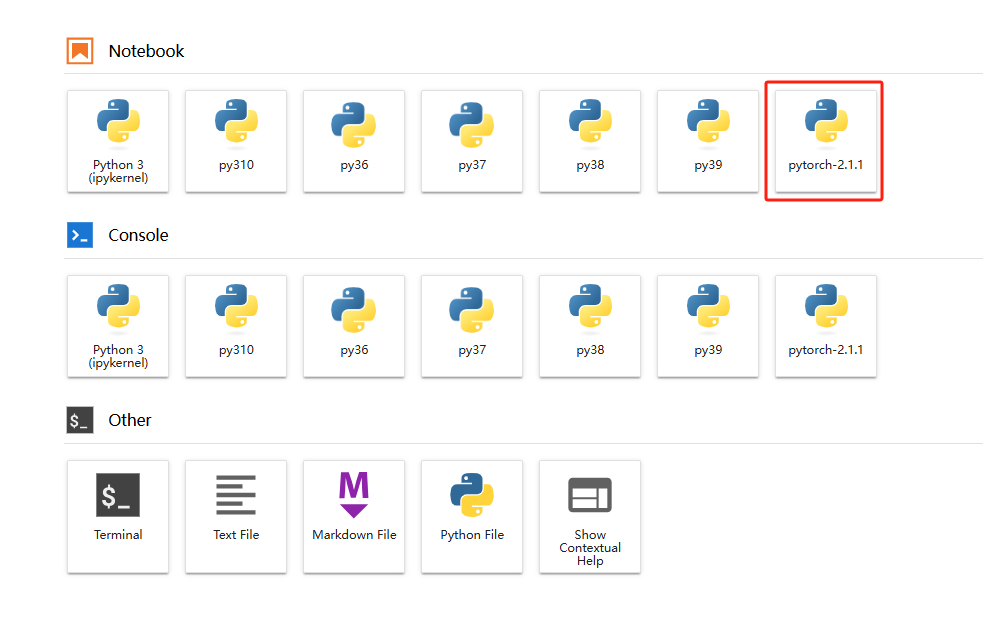
3. 打开 pytorch-2.1.1的虚拟环境,输入如下内容,并点击上面的运行按钮:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
- 查看当前安装的PyTorch版本号、是否支持GPU
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.ones(5, 5).to(device)
y = torch.randn(5, 5).to(device)
z = x + y
print(z)
- 测试GPU计算,会在GPU上创建一个5x5的矩阵x和y,然后将它们相加得到z,并输出结果

公共集群作业方式
平台公共集群提供了多个pytorch的anaconda环境,用户在申请GPU资源后,可以直接加载使用
用户如果没有平台作业提交的经验,可以先查看 帮助中心 - 作业系统部分,了解作业提交的基本概念和操作方法。
1. 准备 pytorch 测试demo,内容如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 生成一些非线性示例数据
# y = sin(x) + 噪声
np.random.seed(0)
x_data = np.linspace(-2 * np.pi, 2 * np.pi, 100).reshape(-1, 1)
y_data = np.sin(x_data) + 0.1 * np.random.randn(*x_data.shape)
# 转换为 PyTorch 张量
x_train = torch.tensor(x_data, dtype=torch.float32)
y_train = torch.tensor(y_data, dtype=torch.float32)
# 定义一个简单的多层感知机模型
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.hidden = nn.Linear(1, 64) # 隐藏层,1个输入特征,64个输出特征
self.relu = nn.ReLU() # 激活函数
self.output = nn.Linear(64, 1) # 输出层,64个输入特征,1个输出特征
def forward(self, x):
x = self.hidden(x)
x = self.relu(x)
x = self.output(x)
return x
# 初始化模型、损失函数和优化器
model = MLP()
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器
# 训练循环
num_epochs = 1000
losses = []
for epoch in range(num_epochs):
# 前向传播
outputs = model(x_train)
loss = criterion(outputs, y_train)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录损失
losses.append(loss.item())
# 打印损失(每100个epoch打印一次)
if (epoch+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 打印训练后的模型参数
# for name, param in model.named_parameters():
# if param.requires_grad:
# print(f'{name}: {param.data}')
- 构建一个简单的多层感知机(MLP)来拟合非线性数据。这个示例包括数据生成、模型定义、训练循环以及最终的训练结果输出。
- 在用户的个人目录下新建名称为 pytorch-demo.py 的脚本文件,并将以上内容粘贴进脚本中
下载Demo文件
2. 准备作业提交脚本,内容如下:
#!/bin/bash
#SBATCH --job-name=pytorch-demo
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=10
#SBATCH --output=%j.out
#SBATCH --error=%j.err
#SBATCH --partition=gpu
#SBATCH --gres=gpu:1
source ~/.bashrc
source /opt/app/anaconda3/bin/activate pytorch_2.2.2
python pytorch-demo.py
- 脚本中,指定gpu分区,申请了1个节点、10个CPU核心、1张GPU卡
- 在用户的个人目录下新建名称为 pytorch-test.sh 的脚本文件,并将以上内容粘贴进脚本中
3. 使用sbatch pytorch-test.sh 命令提交作业
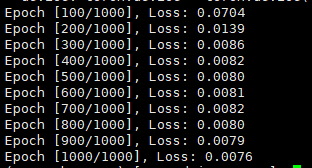
作业提交后,查看 %j.out 脚本,看到如下内容即表示成功使用pytorch进行训练
常见问题:
参考链接:
https://pytorch.org/
